
Google DeepMind võitis matemaatikaolümpiaadil kuldmedali
Ülevaade: Google DeepMind teatas, et nende uus Gemini mudel on saavutanud 2025. aasta rahvusvahelise matemaatikaolümpiaadi kuldmedali taseme, mida väitis ka OpenAI oma uue mudeli kohta.
Detailid:
- DeepMind teatas, et nad andsid oma Gemini mudelile lahendada samad ülesanded sama aja jooksul (4,5 tundi) nagu Rahvusvahelise Matemaatikaolümpiaadi (IMO) osalejatele.
- Gemini lahendas kuuest ülesandest viis – sealhulgas algebra, geomeetria ja arvuteooria ning sai 35 punkti 42-st, mis vastab kuldmedali tasemele.
- Eelmisel aastal sai DeepMind hõbemedali, kuid seekord suutis nende mudel kõik vastused esitada selges ja loomulikus keeles.
- Ka OpenAI väitis, et nende mudel saavutas sarnase tulemuse, kuid neil ei olnud ametlikku koostööd olümpiaadiga, vaid vastuseid hindasid hoopis endised võitjad.
- DeepMindi tulemused aga kontrollisid ametlikult IMO hindajad, kasutades samu reegleid nagu õpilaste puhul.
Miks see on oluline: Kuigi DeepMind ja OpenAI lähenesid erinevalt, näitavad mõlemad tulemused, et tehisaru areneb kiiresti ja suudab lahendada keerulisi matemaatika ülesandeid. Küsimus pole enam selles, kas AI suudab kõik 6 olümpiaadiülesannet ära lahendada, vaid millal ta suudab neid lahendada.
Alibaba Qwen3 juhib avatud lähtekoodiga arendust
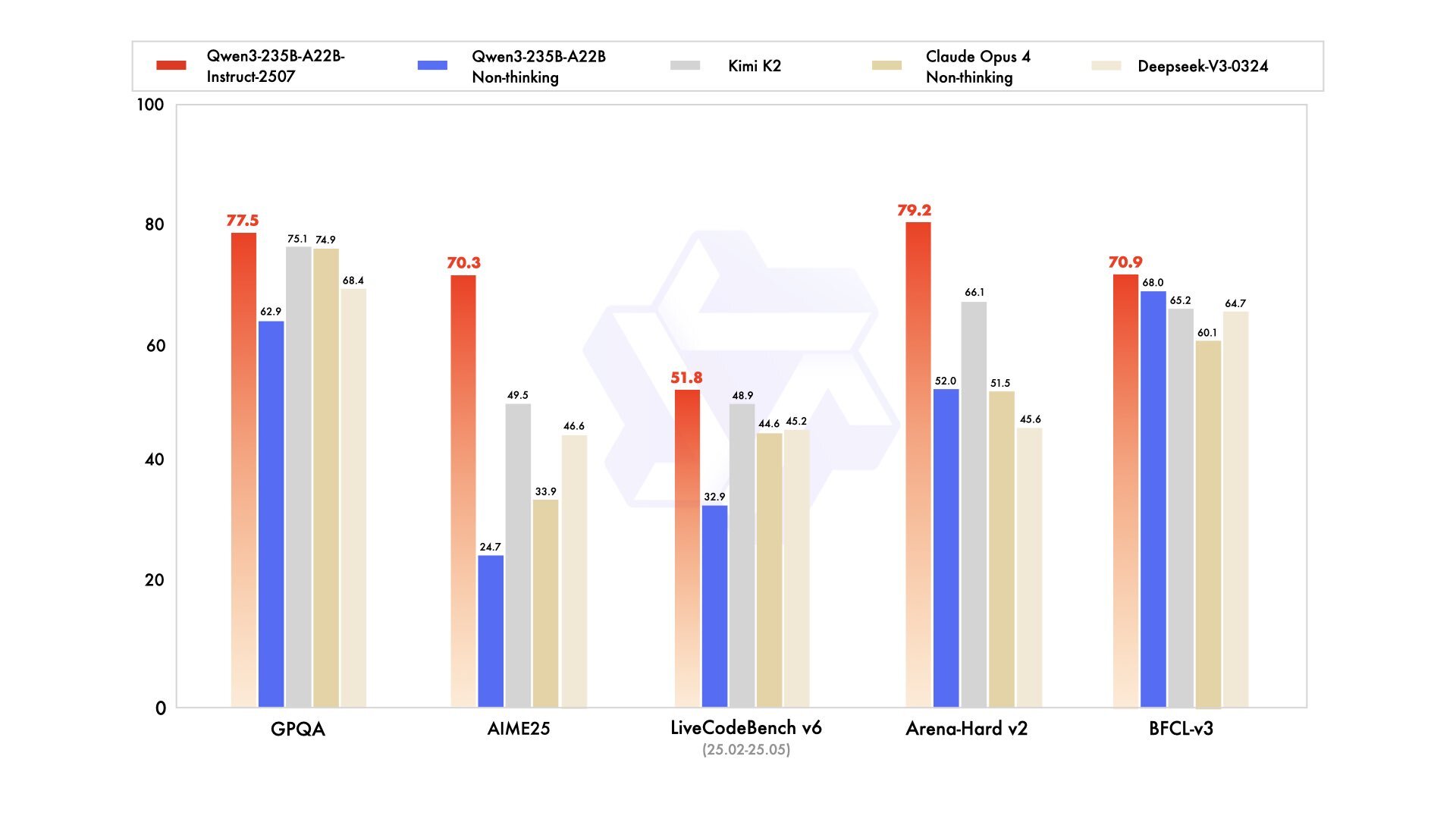
Ülevaade: Alibaba Qweni meeskond on avatud koodiga arenduses üks liidritest: nende uus Qwen3 mudel on parem kui Kimi K2 ja suudab konkureerida isegi parimate kinniste tehisarudega nagu Claude Opus 4,.
Detailid:
- Alibabal on uus lähenemine, kus nad treenivad õpetamis- ja mõtlemismudeleid eraldi kogukonna tagasiside põhjal.
- Uues versioonis kasutatakse 22 miljardit aktiivset parameetrit kokku 235 miljardist, pakkudes paremat jõudlust. Kontekstiaken on suurusega 256K.
- Qwen3 ületab Moonshot AI Kimi K2 mudelit ning pakub väljakutset ka juhtivatele suletud mudelitele nagu Claude Opus 4 ja GPT-4o-0327.
- See mudel on täielikult avatud lähtekoodiga ning saadaval tasuta vaikimisi mudelina Qwen Chat’is, Alibabale kuuluvas ChatGPT alternatiivis.
Miks see on oluline: Hiina meeskond on teinud olulise täiustuse avatud lähtekoodiga AI-s, vaatamata läänemaailma kiipide piirangutele. See edu demonstreerib Hiina kasvavat mõju tehisintellekti uuenduste vallas mitte ainult tehniliste oskuste, vaid ka avatuse ja globaalse mõjuga strateegiate kaudu.
Ajust inspireeritud samm-sammuline mõtlemismudel
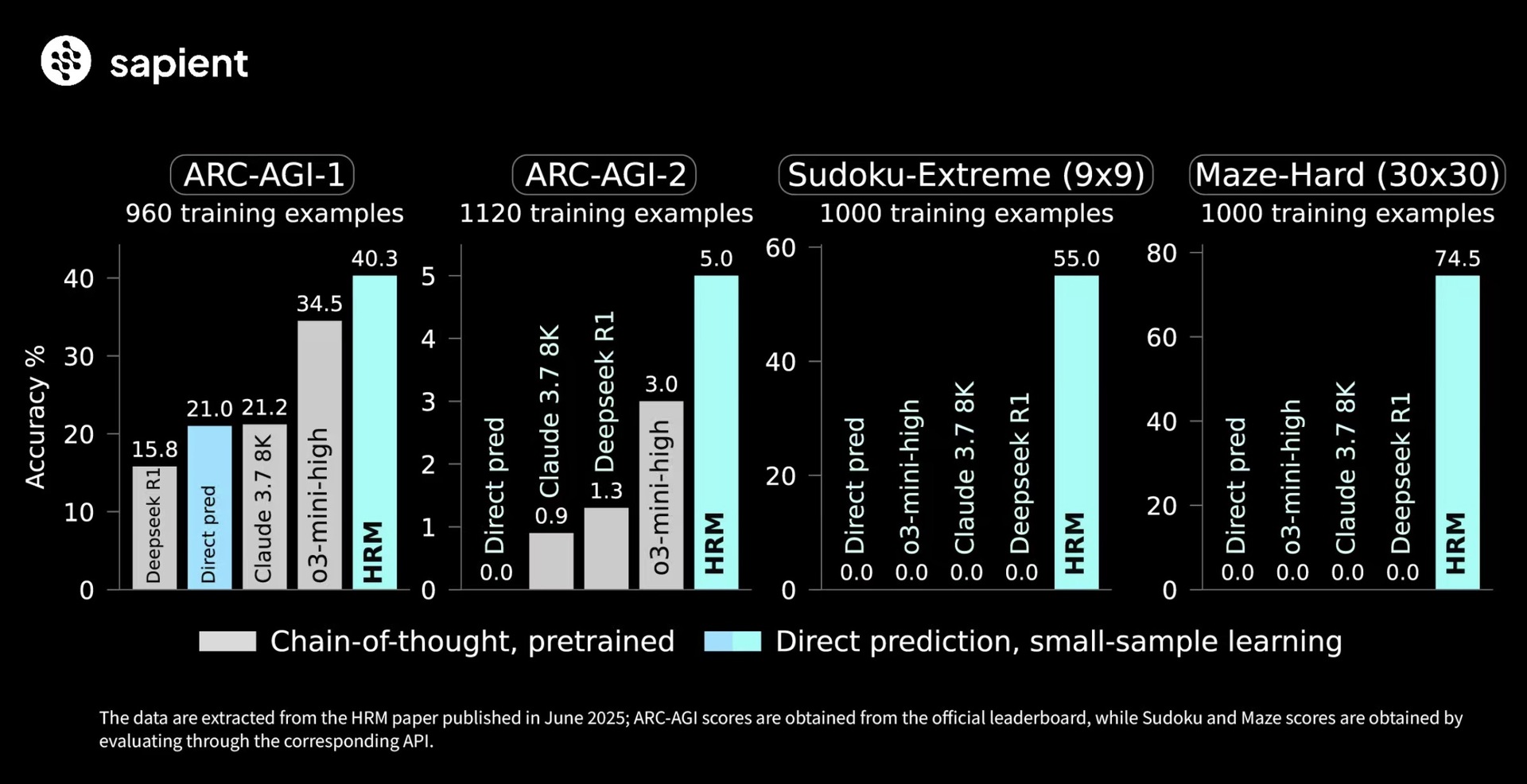
Ülevaade: Sapient Intelligence tutvustas uut avatud koodiga tehisaru mudelit, mis suudab keerulisi ülesandeid nagu ARC-AGI ja Sudoku lahendada vaid 27 miljoni parameetriga, see on väga väike ja tõhus mudel.
Detailid:
- HRM töötab kolme aju tööviisi matkiva põhimõtte järgi: info liigub kihiti, vajalik info eraldatakse õigel ajal ja erinevad osad suhtlevad omavahel korduvalt.
- Kõrgem osa mudelist tegeleb plaanide tegemisega, madalam aga täidab ülesandeid kiiresti ja täpselt. Vahepeal liigub mudel automaatse ja teadliku mõtlemise vahel.
- Tänu sellele lähenemisele suutis HRM lahendada keerukaid ülesandeid nagu ARC-AGI 2, Sudoku ja labürindid paremini kui suuremad mudelid nagu Claude 3.7 ja DeepSeek R1.
- See mudel töötab hästi ka siis, kui treeningandmeid on vähe ja ülesanded on keerulised.
Miks see on oluline: Kui tehisaru liigub päriselu otsuste poole, on HRM-i sarnased aju eeskujul loodud ja tõhusad mudelid suur edasiminek. Need suudavad hästi töötada ka siis, kui andmeid on vähe. Sapient kasutab HRM-i juba päriselus, näiteks haruldaste haiguste diagnoosimisel ja täpsemate kliimahinnangute tegemisel.